We present SAGE (Smart Home Agent with Grounded Execution): an LLM-based smart home assistant framework, leveraging a variety of tools.
The common-sense reasoning abilities and vast general knowledge of Large Language Models (LLMs) make them a natural fit for interpreting user requests in a smart home assistant context. LLMs, however, lack specific knowledge about the user and their home, which limits their potential impact. SAGE (Smart Home Agent with Grounded Execution), overcomes these and other limitations by using a scheme in which a user request triggers an LLM-controlled sequence of discrete actions. These actions can be used to retrieve information, interact with the user, or manipulate device states. SAGE controls this process through a dynamically constructed tree of LLM prompts, which help it decide which action to take next, whether an action was successful, and when to terminate the process. The SAGE action set augments an LLM's capabilities to support some of the most critical requirements for a smart home assistant. These include: flexible and scalable user preference management (Is my team playing tonight?"), access to any smart device's full functionality without device-specific code via API reading (Turn down the screen brightness on my dryer"), persistent device state monitoring (Remind me to throw out the milk when I open the fridge"), natural device references using only a photo of the room (Turn on the lamp on the dresser"), and more. We introduce a benchmark of 50 new and challenging smart home tasks where SAGE achieves a 76% success rate, significantly outperforming existing LLM-enabled baselines (30% success rate).
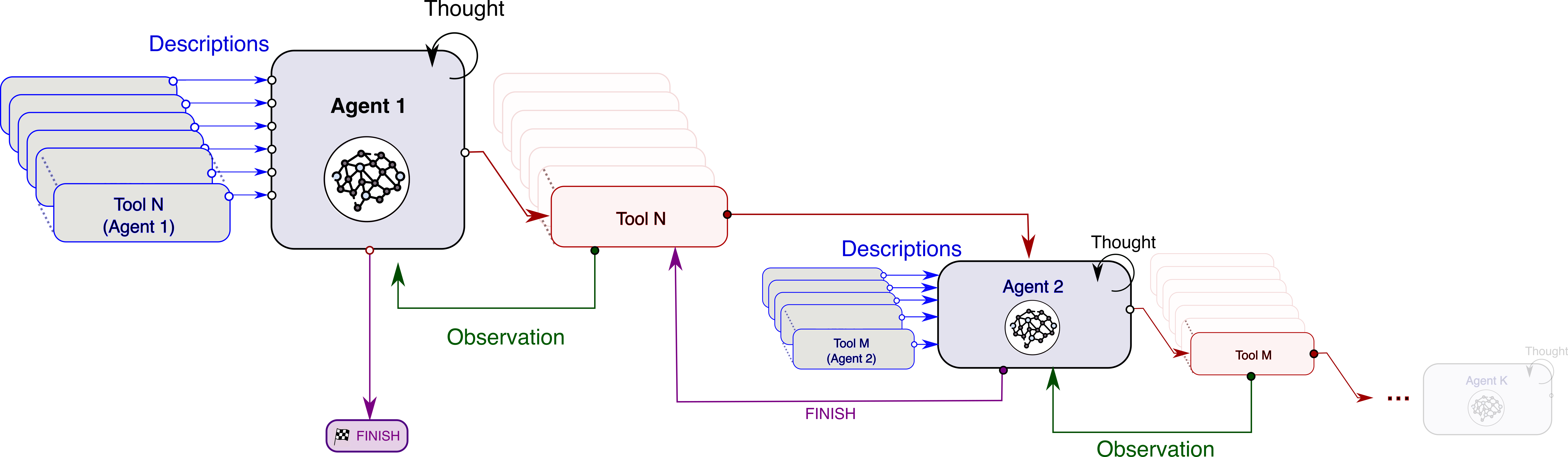
SAGE has access to a variety of tools to carry out complex commands.
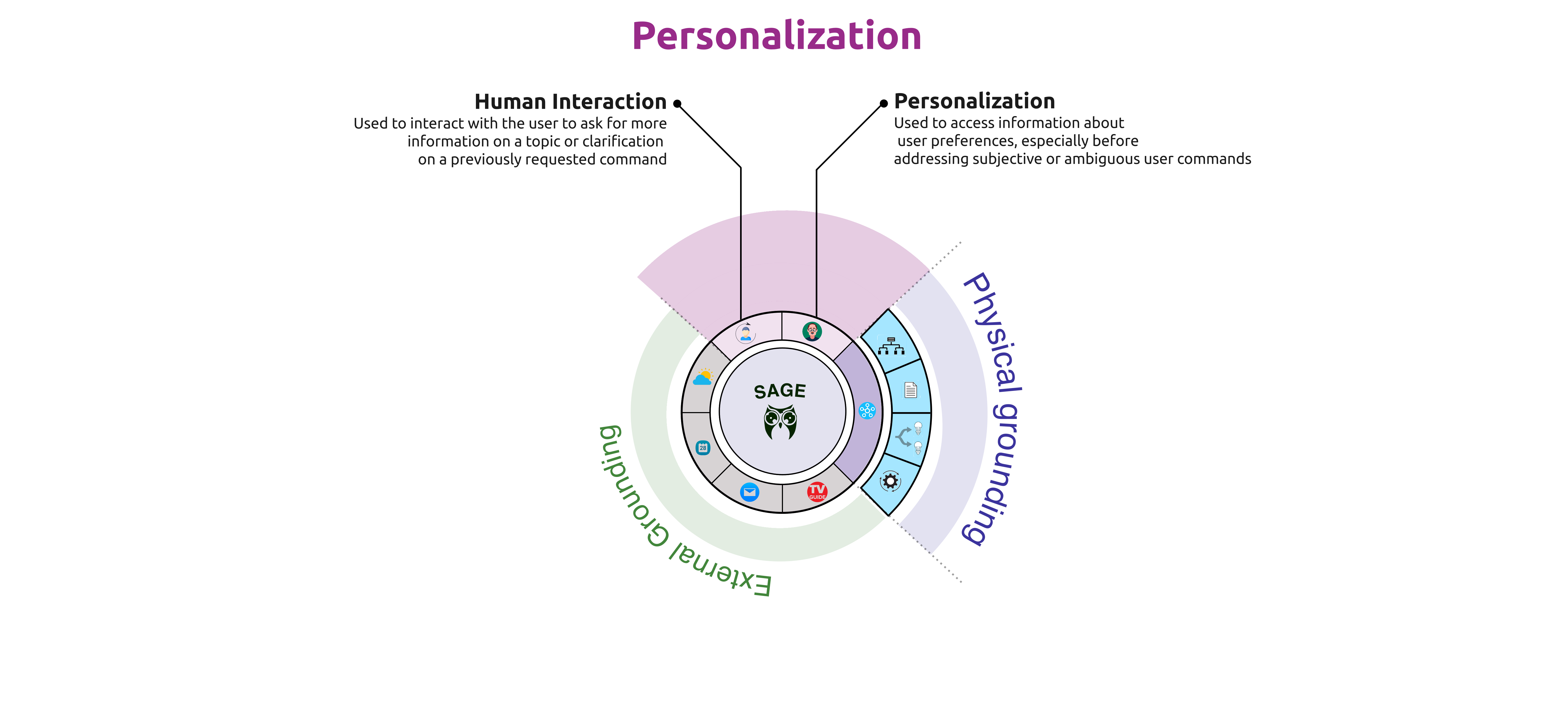
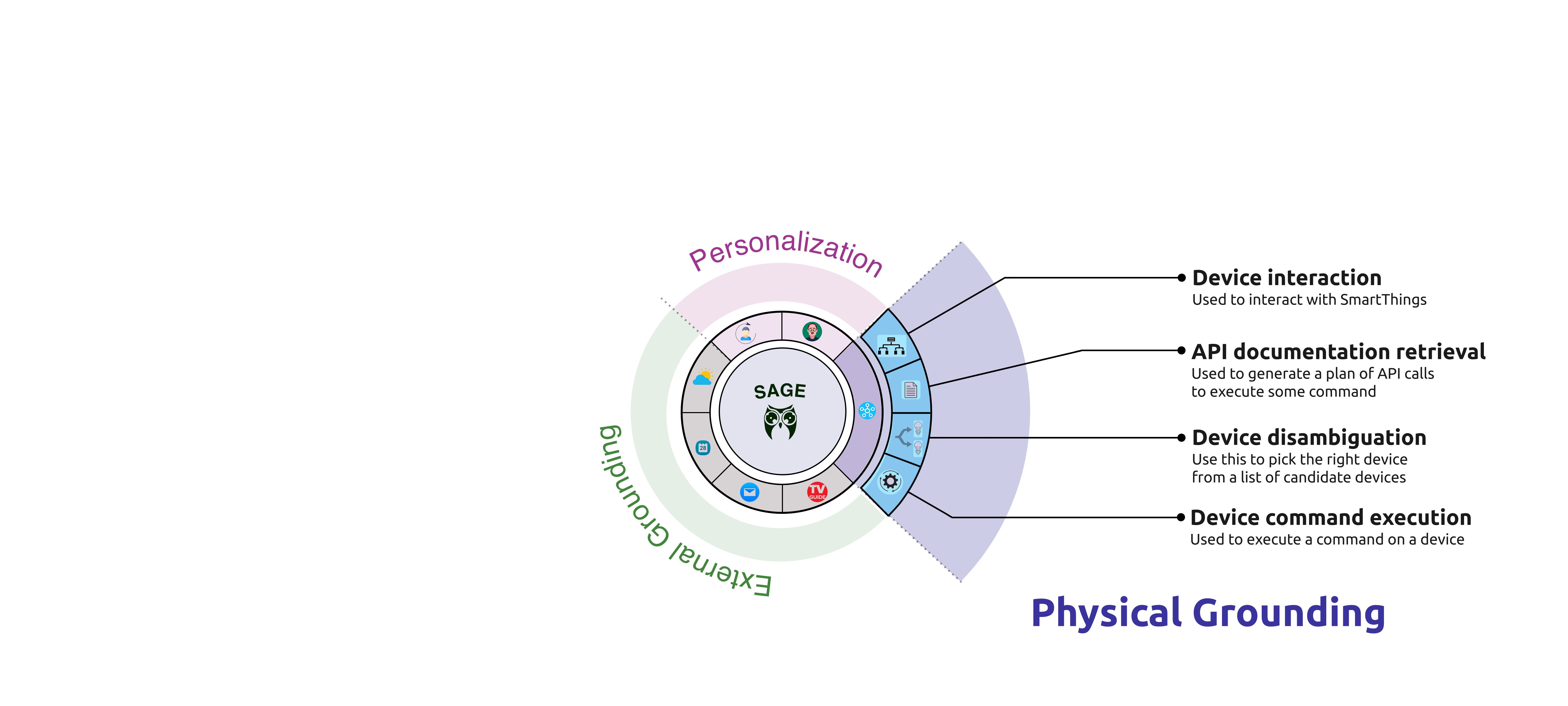
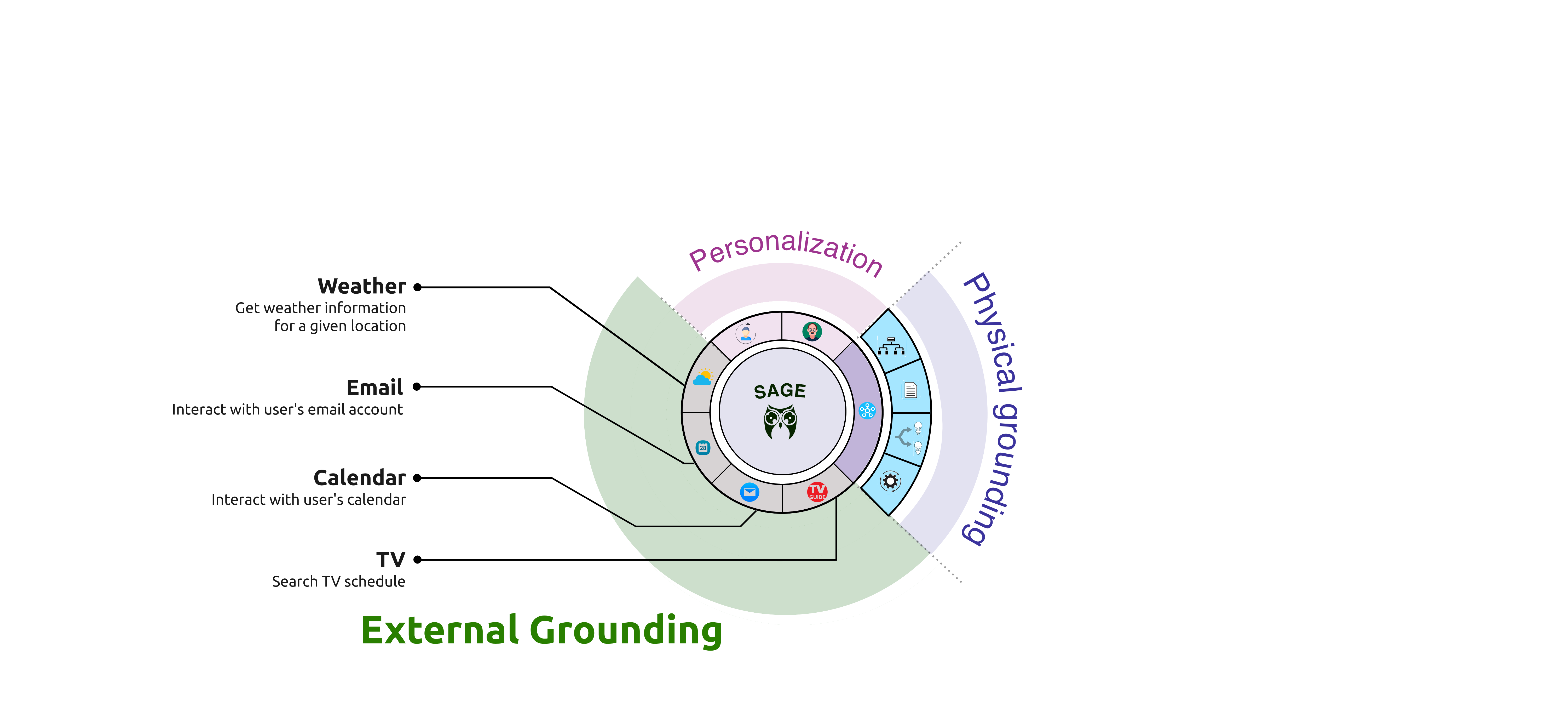
An LLM-based system capable of orchestrating a multitude of tools to support physically grounded and complex decision making.
Data Sources
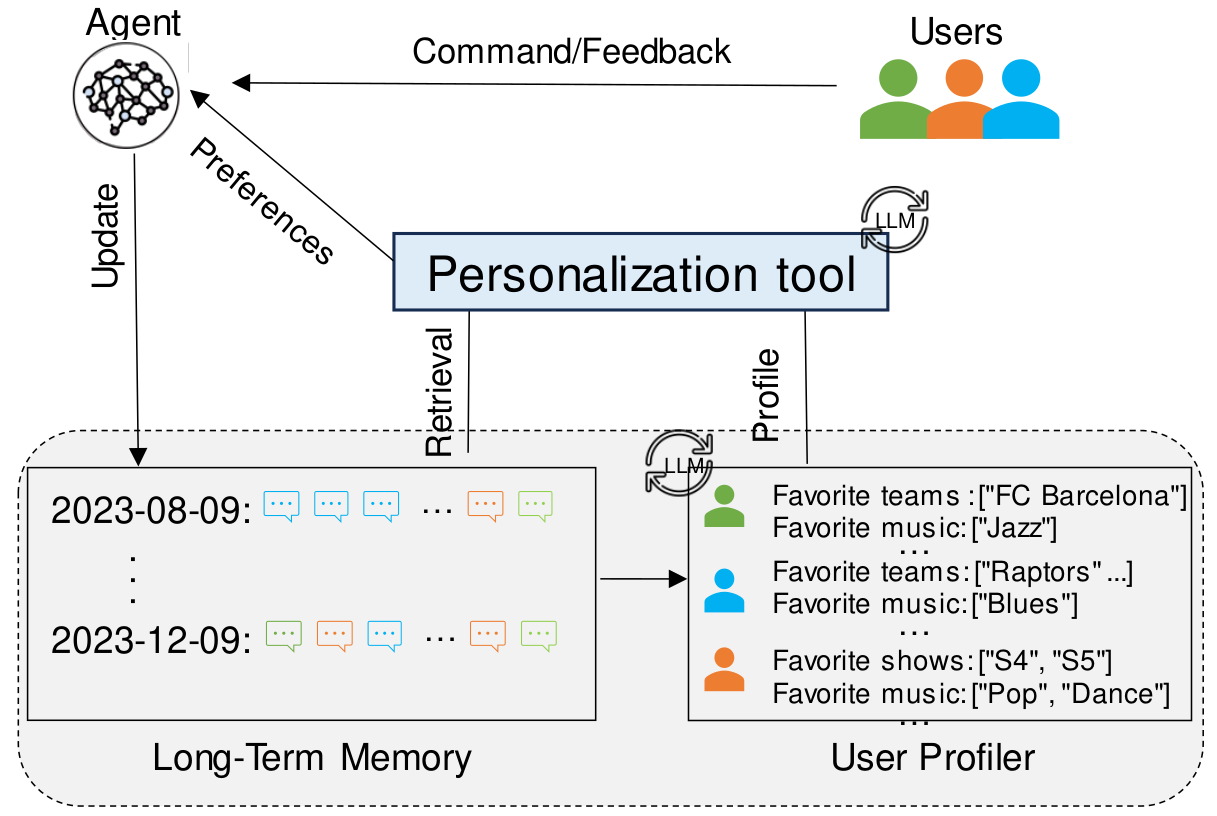
Personalization module
Smart Things Tool enables SAGE to interact with SmartThings devices.
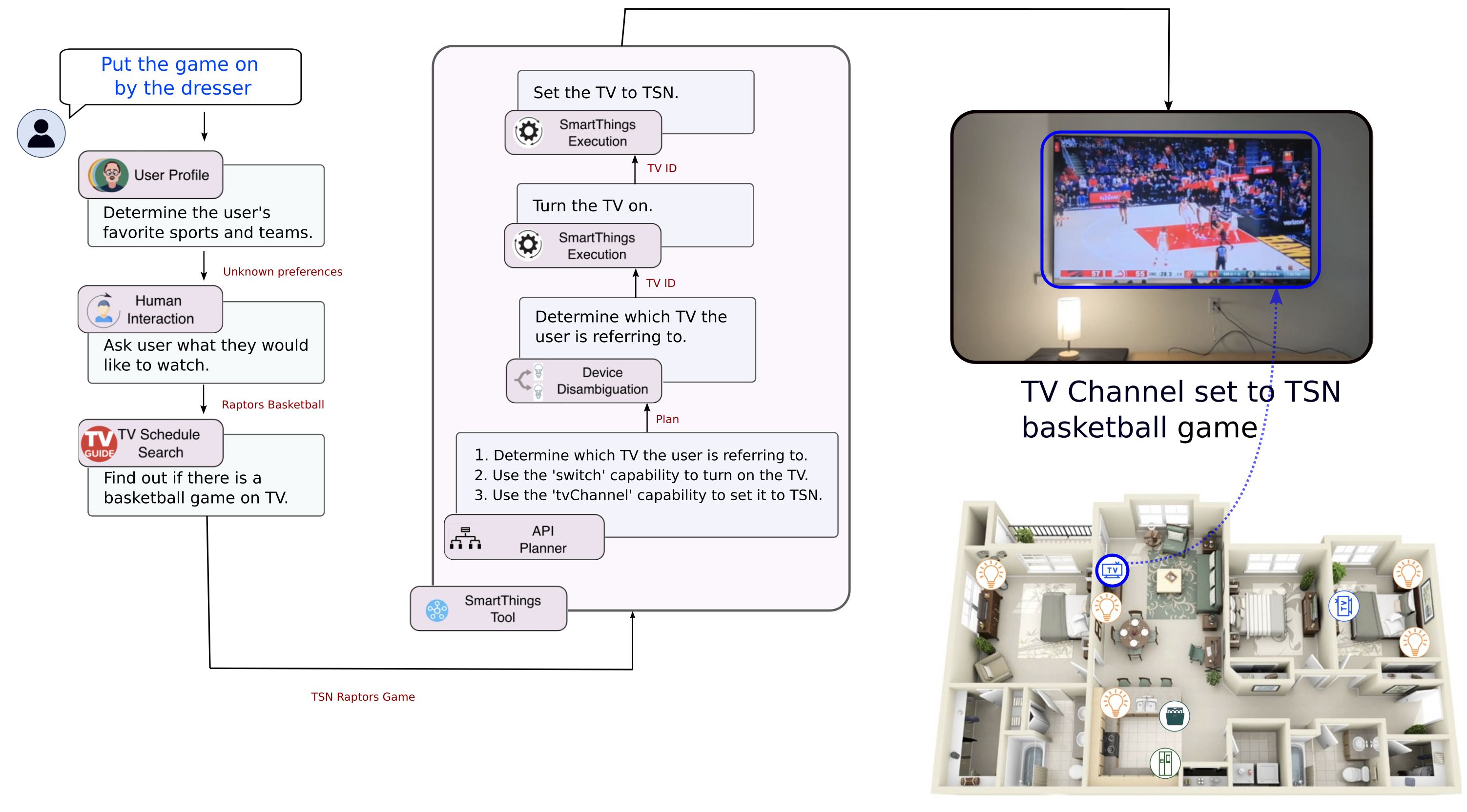
Multi-Step Planning 1. API Planner (device & capability selection) 2. Documentation Retrieval 3. Get Attribute (read state) 4. Execution (send command) Code Free Interaction Leverages online documentation to control SmartThings devices Failure recovery Agent usually automatically recovers from failures like incorrectly formatting the request, or reading the wrong attribute.
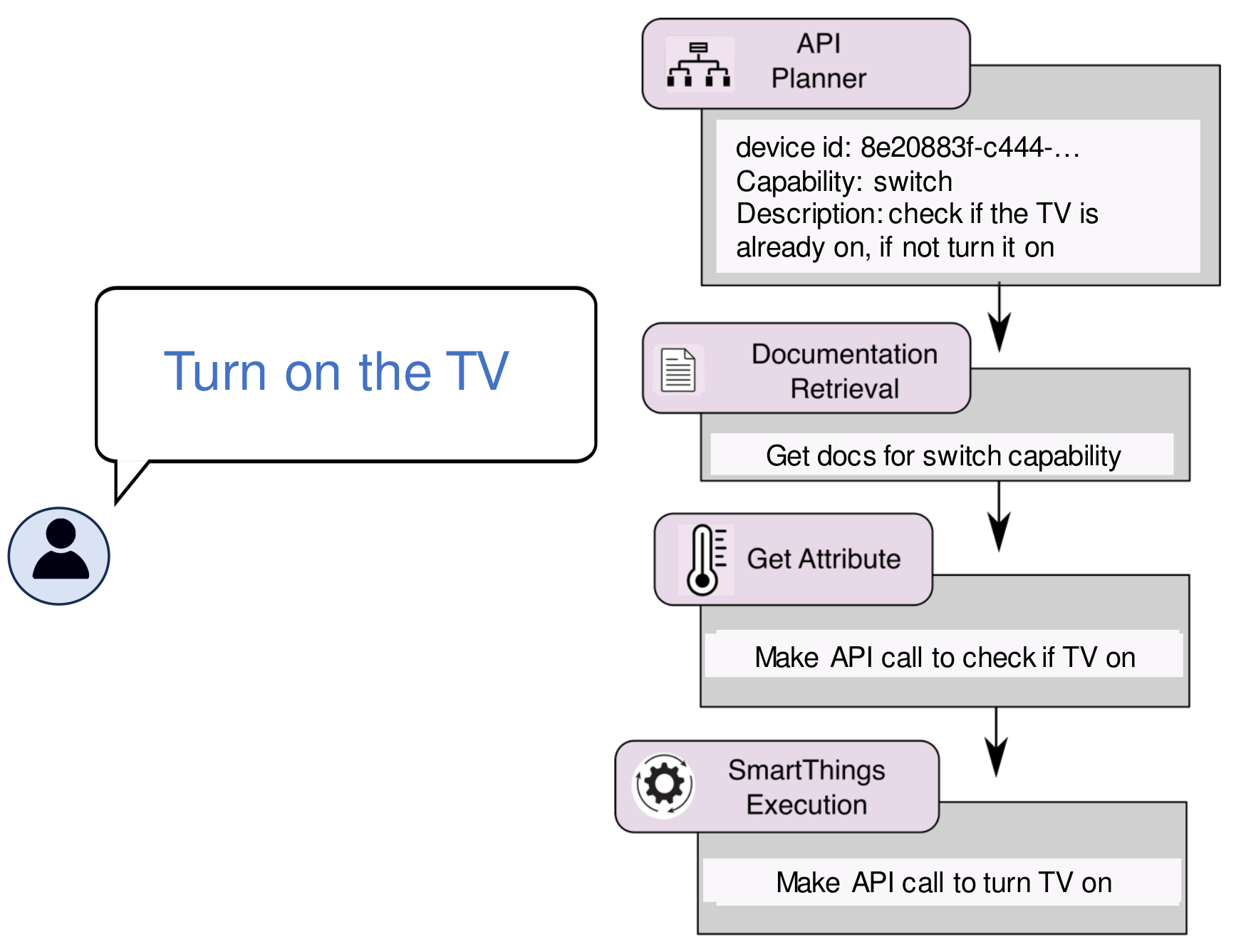
SAGE device interaction execution process
A framework that can remember long-term objectives (e.g. "turn on the lights when the TV turns off").
Code Generation We let the LLM generate the code to check the conditions that must be met to execute a command. Code writing process is implemented similarly to the SmartThings tool (planning, documentation reading, etc). Polling A server polls the code generated by LLM, until the trigger condition is met. Execution Once the condition is met, the command is executed on the device. Flexible and Efficient Retain LLM flexibility without continuously running the agent to poll the condition.
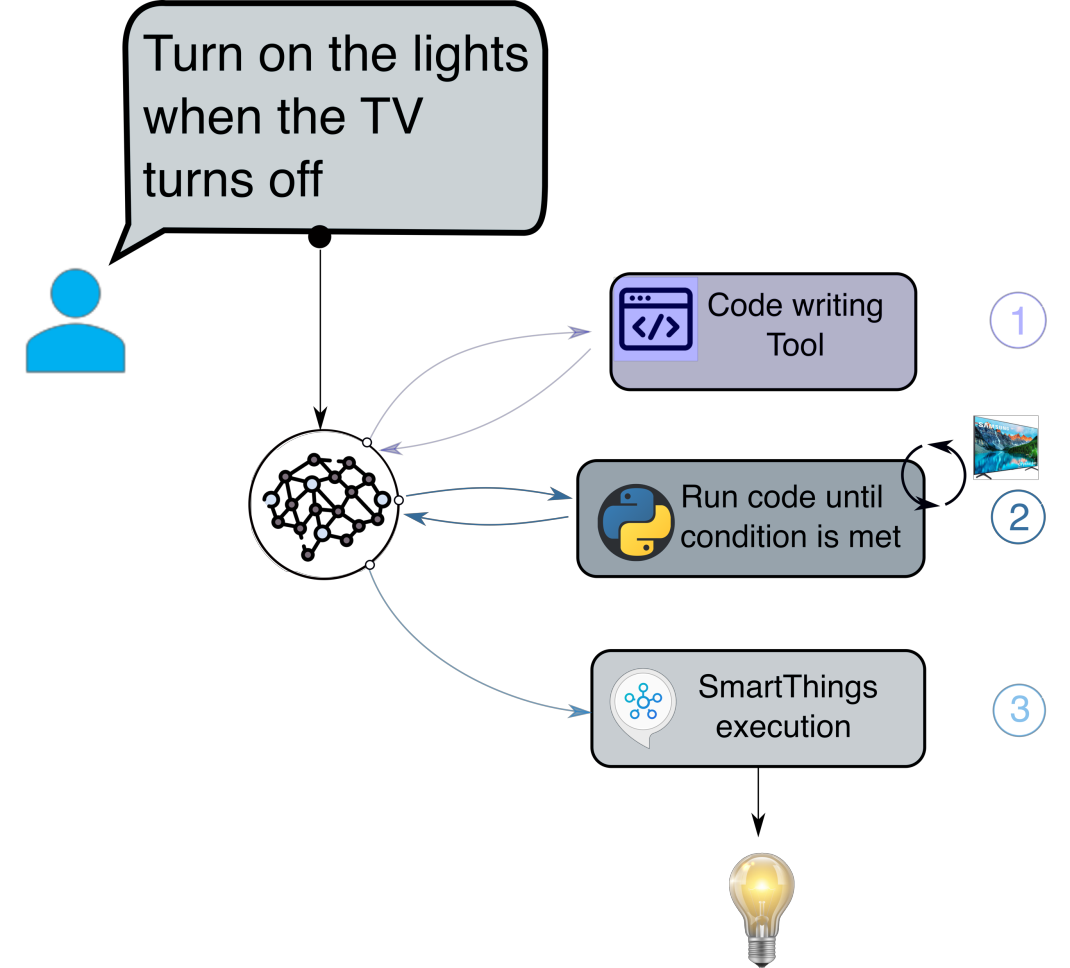
Persistent commands pipeline
Determine which device the user is referencing to by leveraging visual context.
Device Setup Capture a picture of the room where the device is kept. VLM Device Matching Use VLMs (e.g. CLIP) to determine which device best matches the user query.
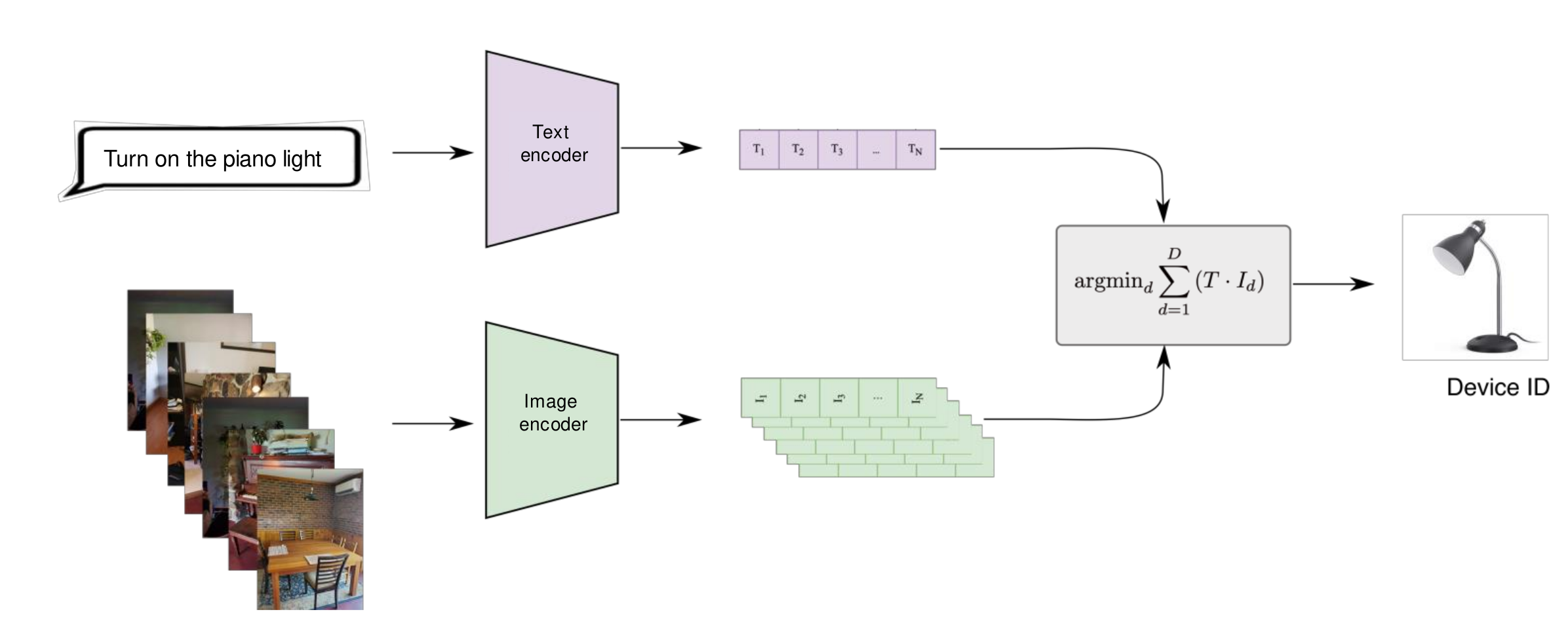
VLM device matching
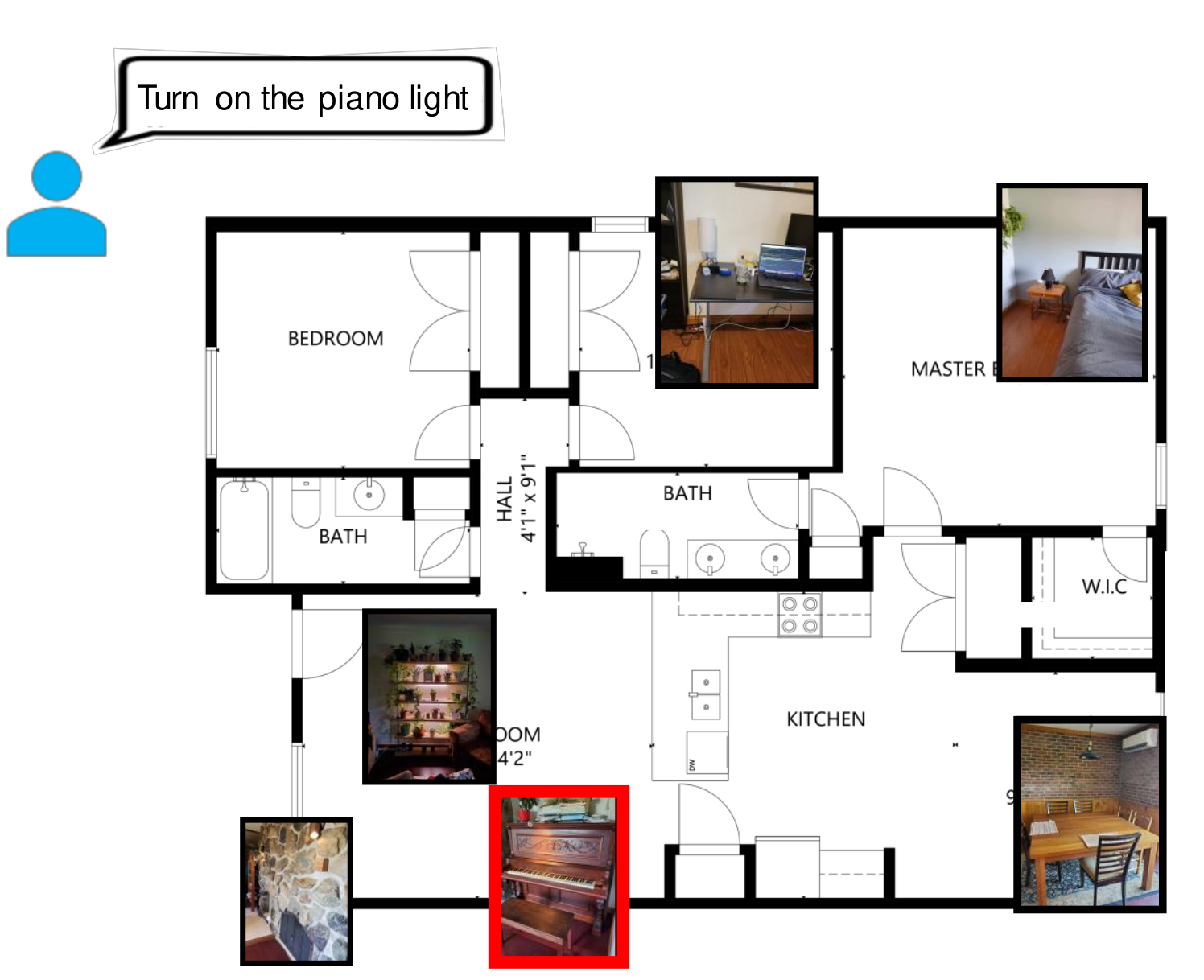
Home layout with multiple connected lights
To evaluate SAGE's performance, we created a dataset of 50 challenging smart home automation test cases which tested the system's ability to be personalized, to resolve user intent from unstructured queries, to resolve devices referred to in natural ways (e.g."the light by the piano"), and to appropriately handle command persistence and chaining. These challenges are very difficult for today's smart home automation systems, but reflect the sophistication smart home users will demand next-generation systems. We compare SAGE against two other baseline LLM smart home assistant approaches: One-Prompt and Sasha (see paper for details). SAGE achieved a success rate of 76% on these tasks. This value, while imperfect, is much higher than that achieved by existing smart home assistants, even those based on powerful LLM technology. Each success required the successful sequential use of many tools, meaning that in fact the number of successful tool uses is much larger than the number of failed ones.
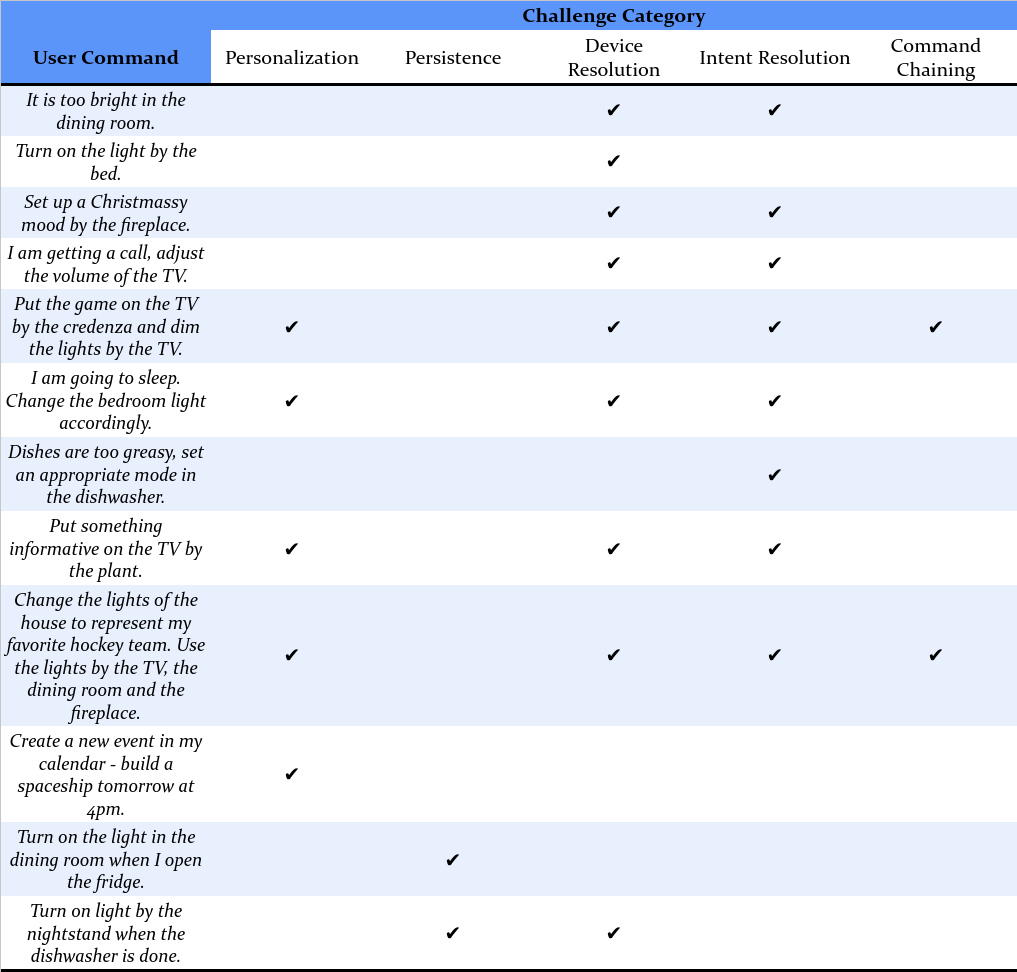
An illustrative subset of the 50 tasks used for evaluation. We classify the test cases according to five types of technical challenges which are difficult for existing systems: Personalization, Persistence, Device resolution, Intent resolution, and Command chaining. The full list can be found on the SAGE code repository.
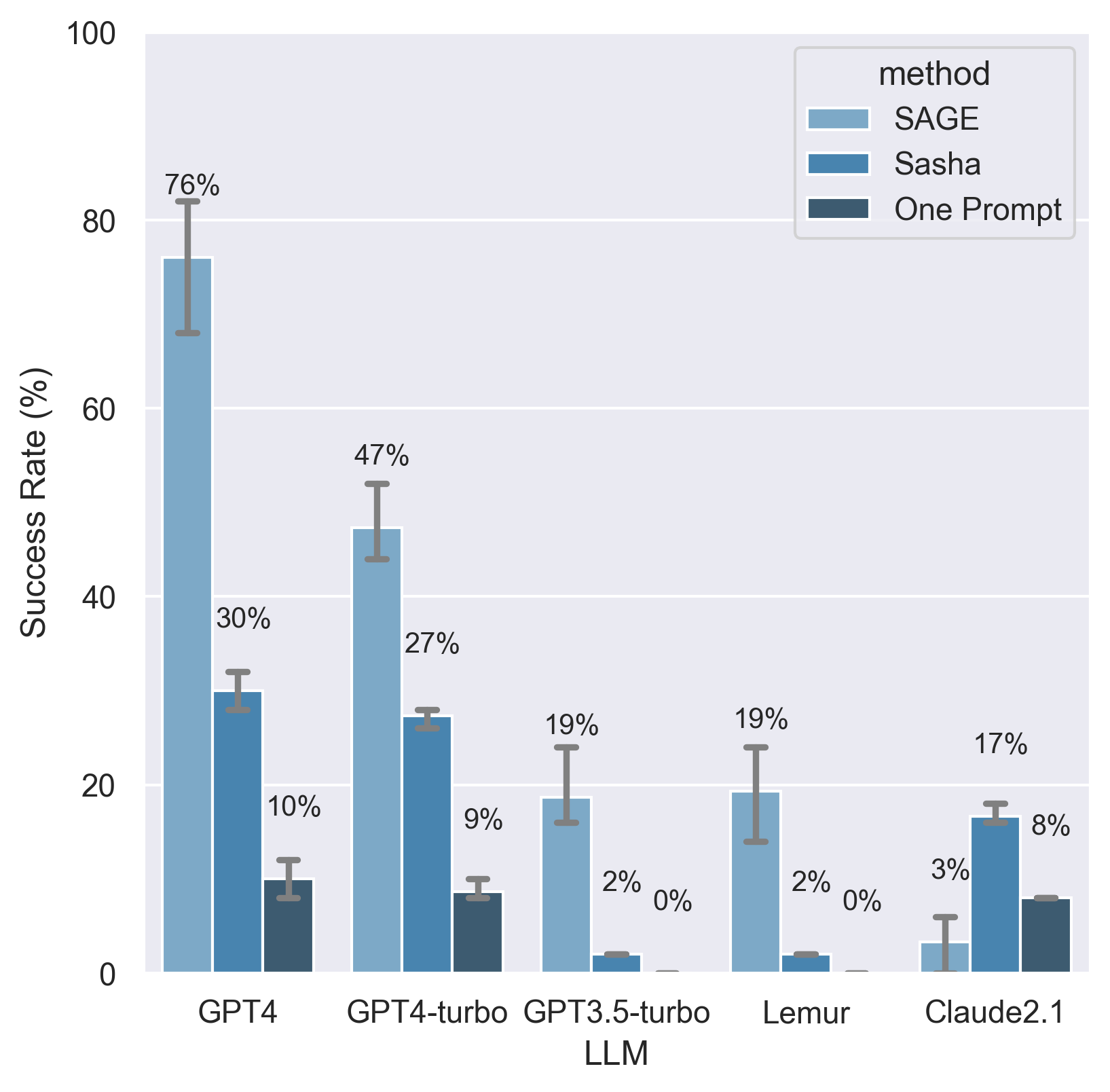
Overall success rates on 50 challenging tasks. SAGE leverages a collection of tools that allow it to integrate a large amount of information into its decision making process, allowing it to outperform other LLM-based methods by a significant margin. Designed primarily for use with GPT-4, it outperforms other methods with a variety of LLMs, including open source models such as Lemur. Error bars indicate max and min scores over the three runs.
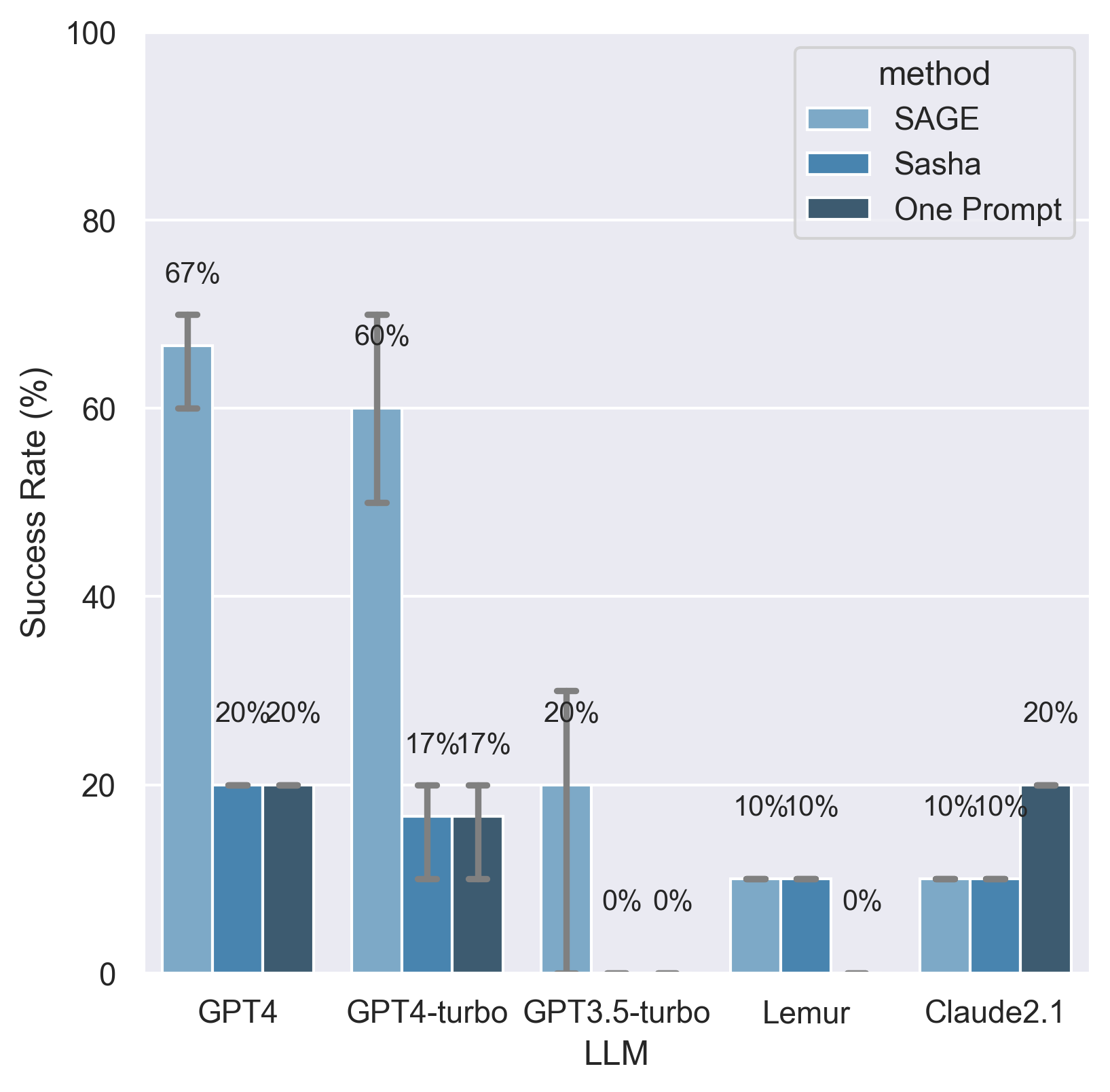
Overall success rates on a "test set" of 10 extra tasks. These tasks were not seen by the SAGE's designers during the iteration process, and serve to validate that the prompts used in SAGE are not over-engineered to a particular task set. Error bars indicate max and min scores over the three runs.
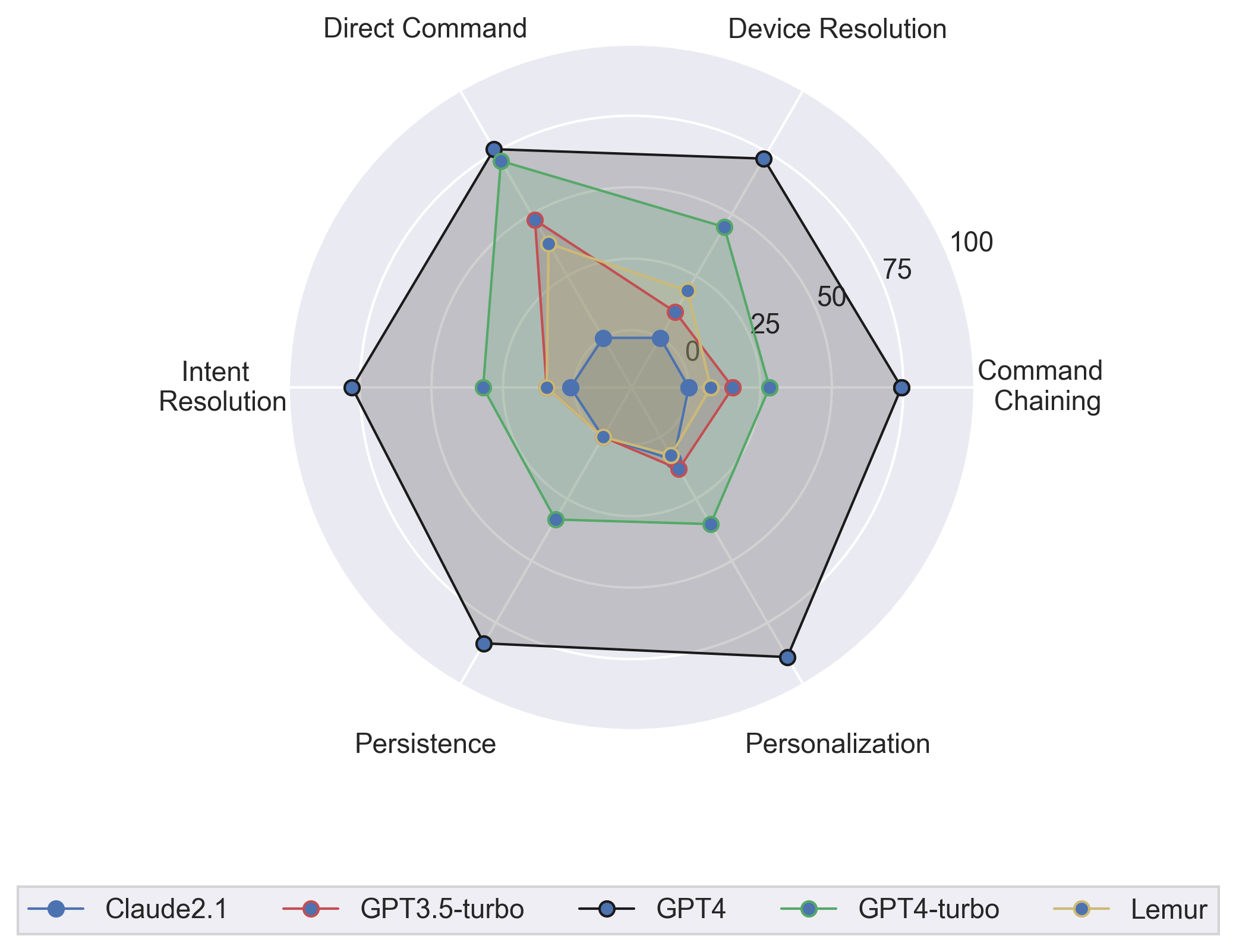
SAGE success rates for each category of challenging tasks on the 50 task set. Note the inner ring of the chart indicates zero success rate, not the center.
@misc{rivkin2023sage,
title={SAGE: Smart home Agent with Grounded Execution},
author={Dmitriy Rivkin and Francois Hogan and Amal Feriani and Abhisek Konar and Adam Sigal and Steve Liu and Greg Dudek},
year={2023},
eprint={2311.00772},
archivePrefix={arXiv},
primaryClass={cs.AI}
}